This project has been my primary focus at Skyworld. Our team's goal is to create an automated pipeline for generating AI-driven short series. I was in charge of the actor performance aspect, specifically generating audio-driven human poses, including body movements and hand gestures, which are crucial for delivering a coherent actor performance. To accomplish this, I explored two approaches: motion retrieval and end-to-end motion generation. The ultimate objectives of this project are as follows:
Implementation Method
Motion retrieval
End-to-end gesture generation methods has shown really great results, but they connot convey appropriate semantic information. Rule based method can generate gesture with satified semantic information. Based on this, I tried to build a motion bank and design retrival rules. More details are shown here Motion retrivalEnd-to-end methods
Diffusion-based methods
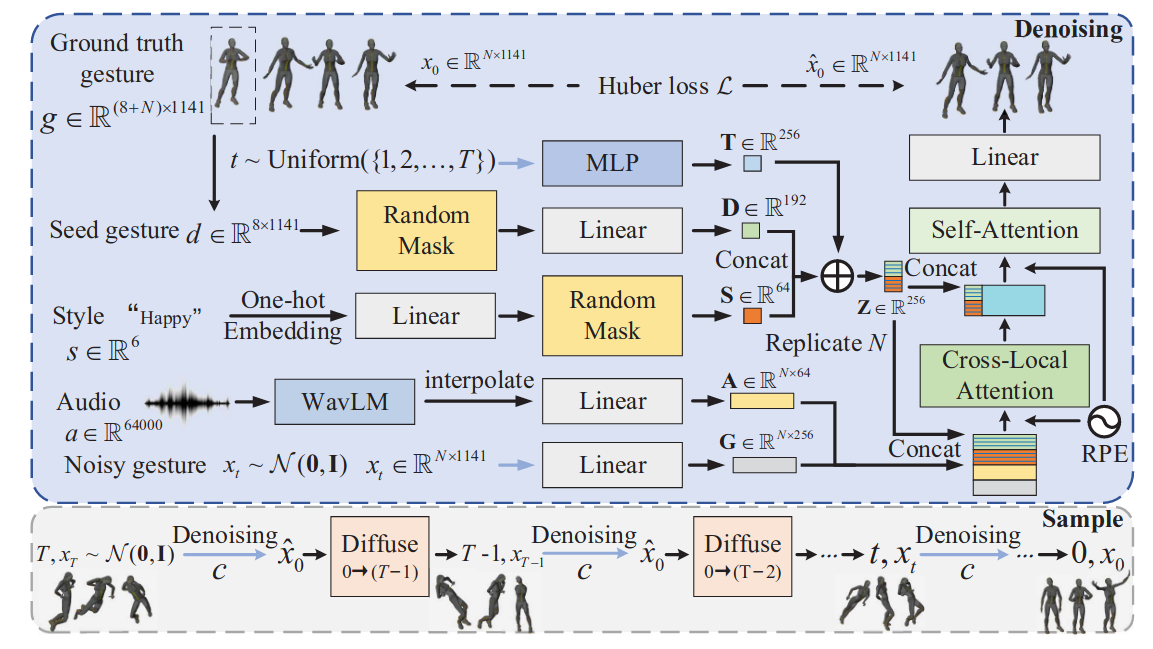
DiffusionstyleGesture: This method, based on transformer-diffusion, produces results with excellent fluidity. However, the movements tend to be larger, making it more suitable for speech scenarios. This is primarily because the training data is predominantly from speech-related scenes.
Transformer-based method
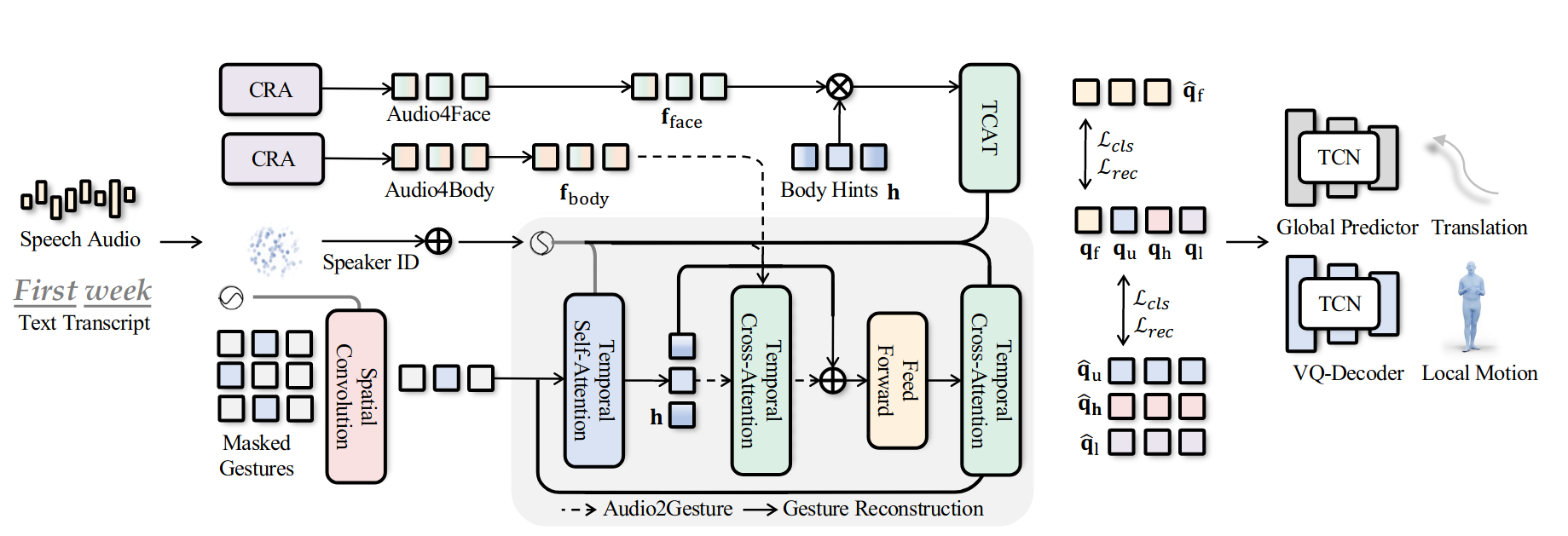
EMAGE: This method uses a fully transformer-based architecture. For network structure considerations, due to the significant differences in movement patterns and ranges for different body parts, it generates hand, upper body, and lower body movements separately. The training data is predominantly from speech scenarios, which results in poorer experimental outcomes with many redundant movements. The dataset used is BEAT2 (SMPL-X), which is divided into BEAT2-Standard and BEAT2-Additional. BEAT2-Standard (27 hours) consists of acted speech with high movement diversity, while BEAT2-Additional (30 hours) includes spontaneous movements. It might be beneficial to train using only BEAT2-Additional. For improving generation quality, EMAGE could be considered as a backbone integrated into the refine stage of audio2photoreal.
End2end + Retrieval
Through combine end-to-end method and rule-based method, we can get human motions, which are both semantically meaningful and smooth. Here are some method, we can refer to.Semantic Gesticulator: Semantics-Aware Co-Speech Gesture Synthesis
GesGPT: Speech Gesture Synthesis With Text Parsing from ChatGPT
Results
DiffusionstyleGesture:
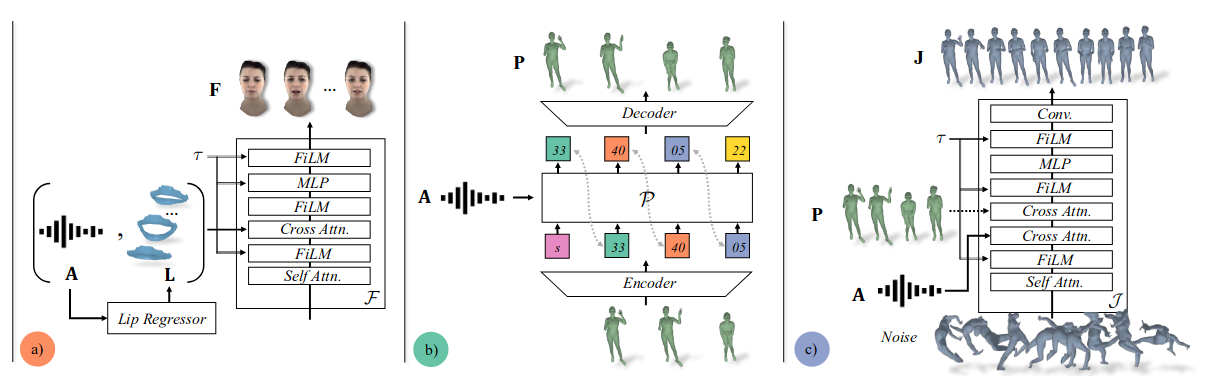
Audio2Photoreal
EMAGE
Retrieval-Augmented:
The core approach involves retrieving poses from the semantic pose bank to identify and insert appropriate poses at their specified positions within the text. I experimented with a word-level retrieval method, utilizing ChatGPT to generate relevant semantic words based on prompts. For Pose Space Merging, we face two primary challenges:
The results were often redundant with mismatched contextual information. It may be beneficial to consider sentence-level Retrieval methods in the future for better context matching.